《Spark核心技术与高级应用》——3.3节独立应用程序编程
本文共 3194 字,大约阅读时间需要 10 分钟。
本节书摘来自华章社区《Spark核心技术与高级应用》一书中的第3章,第3.3节独立应用程序编程,作者于俊 向海 代其锋 马海平,更多章节内容可以访问云栖社区“华章社区”公众号查看
3.3 独立应用程序编程
不同于使用Spark Shell自动初始化SparkContext的例子,独立应用程序需要初始化一个SparkContext作为程序的一部分,然后将一个包含应用程序信息的SparkConf对象传递给SparkContext构造函数。接下来编写简单应用程序SimpleApp,并描述一些简单的编码流程。3.3.1 创建SparkContext对象编写一个Spark程序,首先创建SparkConf对象,该对象包含应用的信息。SparkConf对象构建完毕,需要创建SparkContext对象,该对象可以访问Spark集群。// 创建SparkConf对象val conf = new SparkConf().setAppName("Simple Application")// 创建SparkContext对象val sc = new SparkContext(conf) 3.3.2 编写简单应用程序
一个常见的Hadoop数据流模式是MapReduce,Spark可以轻易地实现MapReduce数据流,我们通过Spark API创建一个简单的Spark应用程序SimpleApp.scala。import org.apache.spark.SparkContextimport org.apache.spark.SparkContext._import org.apache.spark.SparkConfobject SimpleApp {def main(args: Array[String]) {val logFile = "$YOUR_SPARK_HOME/README.md" // 测试文件val conf = new SparkConf().setAppName("Simple Application")val sc = new SparkContext(conf)val logData = sc.textFile(logFile, 2).cache()val numAs = logData.f?ilter(line =>line.contains("a")).count()val numBs = logData.f?ilter(line =>line.contains("b")).count()println("Lines with a: %s, Lines with b: %s".format(numAs, numBs)) }} 这个程序统计了Spark的README.md中含有“a”的行数和含有“b”的行数。实际需要用Spark的安装路径替换YOUR_SPARK_HOME。
3.3.3 编译并提交应用程序可以采用IDEA生成Jar包的方式,也可以采取sbt或者mvn的方式打成Jar包。以sbt package为例,创建一个包含应用程序代码的Jar包。一旦用户的应用程序被打包,就可以使用$SPARK_HOME./bin/spark-submit脚本启动应用程序。spark-submit脚本负责建立Spark的类路径和相关依赖,并支持不同的集群管理(Local、Standalone、YARN)和部署模式(Client、Cluster),通过提交参数进行区别。1.?使用sbt打成Jar包使用sbt打成Jar包过程如下:sbt package...[info] Packaging {..}/{..}/target/scala-2.10/simple-project_2.10-1.0.jar2.?应用程序提交模板应用程序提交模板如下:./bin/spark-submit \ --class \ --master \ --deploy-mode \ ... # other options \[application-arguments] 选项解释说明:
--class:应用程序入口位置,如org.apache.spark.examples.SparkPi。--master:集群的master的URL,如spark://xxx.xxx.xxx.xxx:7077;或使用local在本地单线程地运行,或使用local[N]在本地以N个线程运行。通常应该由运行local进行测试开始。--deploy-mode:集群部署模式,Cluster模式和Client模式(默认模式)。application-jar:包含应用程序和所有依赖的Jar包的路径。该URL必须是在集群中全局可见的,如一个hdfs://路径或者一个在所有Worker节点都出现的f?ile://路径。application-arguments:传递给主类的main函数的参数。对于Python应用,在的位置传入一个.py文件代替一个Jar包,并且以-py-f?iles的方式在搜索路径下加入Python.zip、.egg或.py文件。常见的部署策略是从同一物理位置,即同一个网关的服务器上提交应用程序。在这种设置中,采用Client模式比较合适。在Client模式中,Driver直接在用户的spark-submit进程中启动,应用程序的输入和输出连接到控制台(console)。因此,这个模式对于涉及REPL(Read-Eval-Print Loop,“读取-求值-输出”循环)的应用程序尤其合适。另外,如果你的应用程序是从远离Worker机器的某台机器上提交的(如你的笔记本电脑上),一般要用Cluster模式,使Drivers和Executors之间的网络延迟最小化。(目前Standalone部署模式、Mesos集群模式和Python编写的应用不支持Cluster模式。)传递给Spark的Master URL可以是如表3-1所示的某个格式。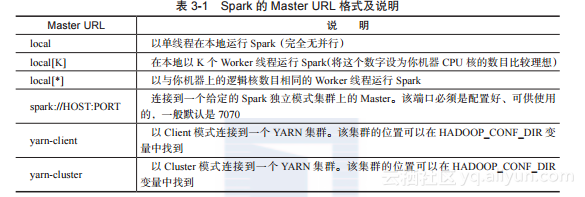
3.以Local模式提交应用程序
以Local模式在4个CPU核上运行应用程序,命令如下:$ YOUR_SPARK_HOME/bin/spark-submit \ --class "SimpleApp" \ --master local[4] \ target/scala-2.10/simple-project_2.10-1.0.jar...4.以Standalone模式提交应用程序以Standalone模式运行应用程序,命令如下:./bin/spark-submit \ --class "SimpleApp" \ --master spark:// *.*.*.*:7077 \ --executor-memory 2G \ --total-executor-cores 10 \target/scala-2.10/simple-project_2.10-1.0.jar5.以YARN模式提交应用程序以YARN模式运行应用程序,命令如下:./bin/spark-submit \ --class "SimpleApp" \ --master yarn-cluster \ # 也可以是 'yarn-client' 模式 --executor-memory 2G \ --num-executors 10 \target/scala-2.10/simple-project_2.10-1.0.jar
转载地址:http://hwdvx.baihongyu.com/
你可能感兴趣的文章
对Java Serializable(序列化)的理解和总结(二)
查看>>
cd命令
查看>>
java二叉树的实现和遍历
查看>>
futurejava前台_京东(Java后端)面试总结
查看>>
swift 生命周期_swift – 保证局部变量中引用的生命周期
查看>>
unittest安装教程_unittest模块使用方法
查看>>
char *需要释放_QT案例词典 释放堆区空间及查询单词
查看>>
python预测你的小孩身高_告别墙上刻线,便捷测取身高——云康宝智能身高测量仪测评...
查看>>
web前端知识点太多_Web前端知识点有哪些 怎么学习小程序基础库
查看>>
wpa群组密钥转动间隔多少好_来电咨询:全国附近锁具销售多少钱一次
查看>>
hive中groupby优化_HiveSQL常用优化方法全面总结
查看>>
gis中开始编辑之后显示空间参考_什么是三维GIS ?
查看>>
qt软件占内存太大_游戏太大占手机内存?狂热玩家ROG:1TB小意思
查看>>
openwrt配置内核驱动_如何将驱动封装到Linux ISO?
查看>>
tomcat线程释放时间_玩转Tomcat监控管理
查看>>
安装vs2017出现闪退现象_设计师总结:卫生间蹲便器安装施工方法,避免出现反臭现象...
查看>>
天线为什么会有多次谐振_【对讲机的那点事】常用的业余无线电天线你了解多少?...
查看>>
flyme禁止系统更新_六大国产手机系统,MIUI成香饽饽,氢OS被狂吐槽
查看>>
用python画生日祝福短信_Python|送给朋友的生日祝福
查看>>
学术诚信的重要性_出国留学论学术诚信的重要性
查看>>